
BigQuery ML Clustering or Segmentation (K-Means)
Overview
This is not an officially supported Google product.
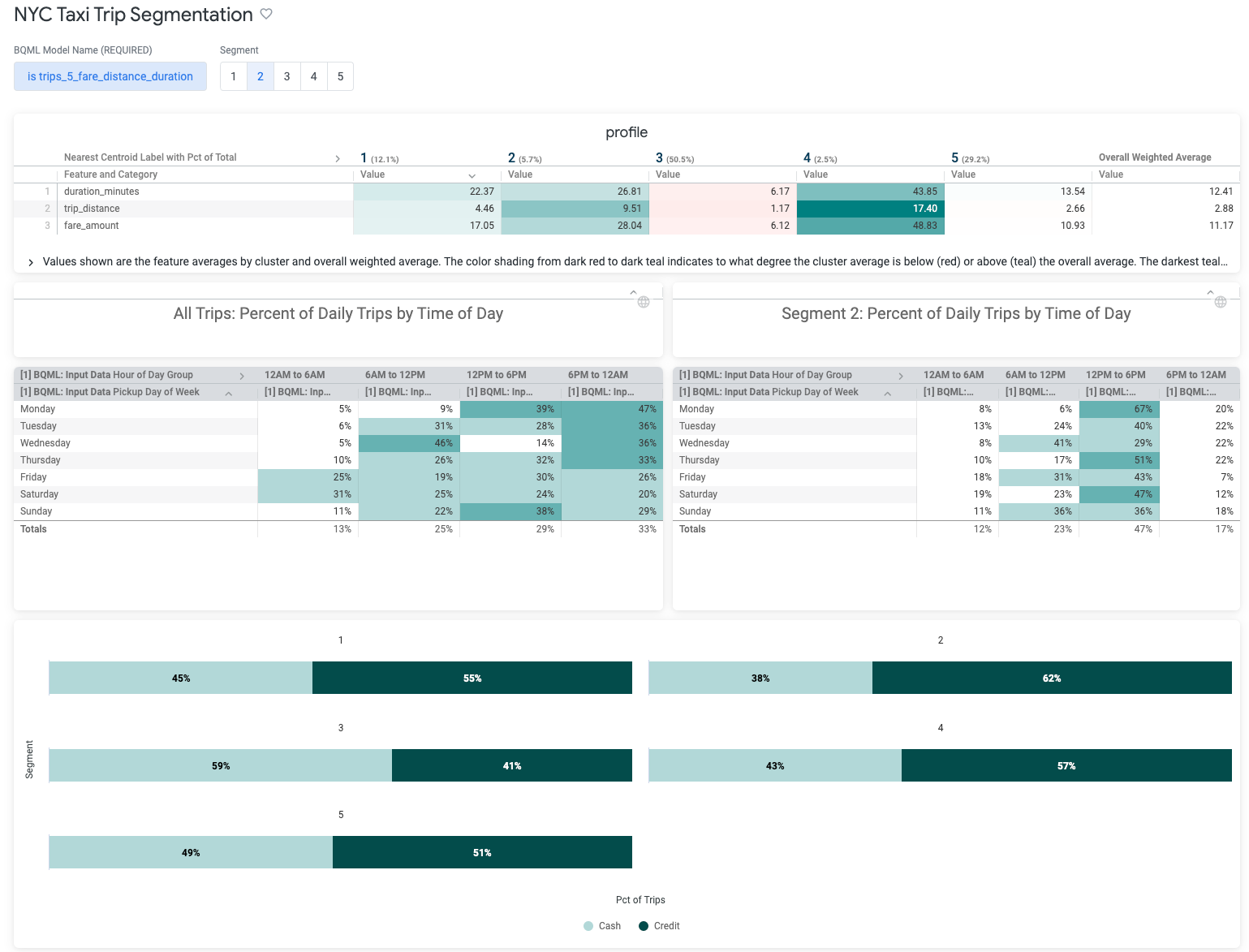
A K-means clustering algorithm is an unsupervised machine learning technique used for data segmentation; for example, identifying customer segments, fraudulent transactions, or similar documents. Using this Block, Looker developers can add this advanced analytical capability right into new or existing Explores, no data scientists required.
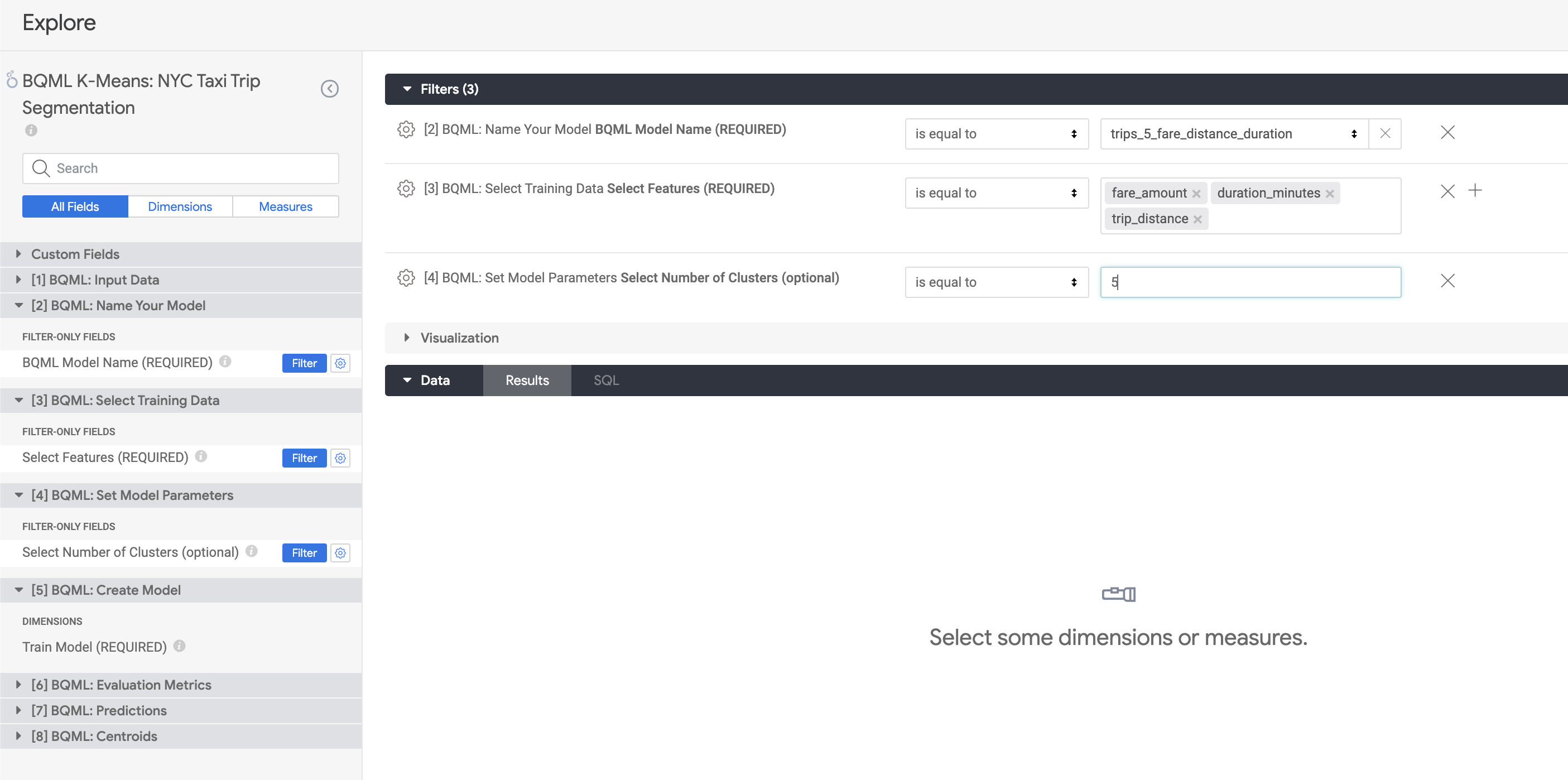
Using this Block, you can integrate Looker with a BigQuery ML K-Means model to get the benefit of clustering and segmenting data using advanced analytics, without needing to be an expert in data science. Based on the input fields you select, this Block:
- Divides data into similar clusters or segments (i.e. groups).
- Ensures data in each group are as similar as possible.
- Ensures each group is as dissimilar from other groups as possible.
This Block gives business users the ability to identify clusters or segments in data using a new or existing Explore. Explores created with this Block can be used to train multiple K-Means models, evaluate them, and access their predictions in dashboards or custom analyses.
Learn more in the associated BigQuery ML Tutorial.
Step by Step instructions for implementation are in the Block Readme